

Nowadays, we can’t imagine the efficient functioning of an online shop without cache. There are many different cache systems for Magento platform (e.g. memcache, redis cache, varnish, etc.) and application of the appropriate system depends on the specifics of a shop and on the expected load to which a particular shop will be exposed. However, what should we do if because of heavy load the cache technically fulfills its role and yet the application fails (as if the cache didn’t work)?
We have encountered such a case in the context of Redis Cache at one of the major projects and I would like to share my experiences with you :) Below I’m going to describe the problem we came across, what sparked our curiosity in the search for the cause of the problem, what was the real reason of the problem and finally – what was its solution.
The problem
On one of the big shops that we maintain (nearly 80 000 products, communication with multiple external systems, nearly 800 requests per minute in peak periods), a puzzling problem with redis cache started to occur. On random days, just before a peak period, the shop performance radically decreased.
When we analyzed the shop, we didn’t notice any script running at the time that would create heavy load, response times of external systems which data is processed synchronously were normal, the database worked efficiently and redis cache response times were practically the same as off-peak.
The only thing that sparked our attention was the fact that just before the clog the amount of pushed cache keys increased and when it reached more than 600 per second, it was followed by the clog (what is and what causes pushing cache keys will be described later in this article).
It turned out that the problem occurred when the cache was being cleared. After the operation the shop efficiency normalized slowly, as a few moments had to pass before the primary cache rebuilt and the shop returned to its full performance. After rebuilding the primary cache, the shop performance returned to a normal level.
Searching for the cause of the problem
Following the lead of the pushed keys, we found out in Redis documentation that the key push occurs when all available memory is full (redis has various performance policies when the cache is full, more here.
The selected policy of pushing keys (volatile-lru) works in a way that when there is no enough memory available, it takes a random bunch of keys (with set lifetimes – it skips those that are “eternally alive”) and removes the one who was most recently used the least often. That way, it makes room for data for which there is no space in the cache.
So, let’s look at all this in the context of our problem…
The fact that the number of pushed keys was large and growing shows that more and more new data was generated, for which there was no room in the cache. However, this is normal redis operation and of was not the reason for a clog itself.
The problem turned out to be more complex, but we were persistent…
Magento stores data in Redis through two types of SET and HASH (redis alone has more data types, read more here.
HASH is a multi-dimensional array in which the variable is assigned the value you want to remember, as well as other necessary parameters, e.g. lifetime or tags where the value is present. Data in Magento is most frequently stored in the form of HASH.
SET is a one-dimensional array in which each new value is a separate element of the array. In Magento, TAGs are usually stored in the SET format. TAG is designed to hold cache keys in order to delete a specific set of data. Example: having TAG_PRODUCT_ID we can clear the cache of the product only, as it will contain a list of cache keys containing all the values related to this product. In other words, TAGs group multiple values in a particular collection.
How much application data in the cache (HASH) is assigned to TAGs (SET) depends on a developer and which data groups from the cache need to be deleted/updated. Additionally, there is also a global TAG called MAGE which contains all the keys present in the cache.
As you can see, in addition to the data storing certain values, Redis is full of redundant data not doing anything apart from aggregating cache keys and partially prompting the solution to our problem – this data was the cause of clogging.
The real problem
Only the application data (HASH) knows how much time it has left to its “death” (expiration). The data disappears when it “dies”, while the list of keys contained in TAGs (SET) remains.
The expiry of the application data (HASH) is equivalent to pushing mechanism upon reaching full cache (the case of keys pushing is described above) – here TAGs (SET) containing keys of these values remain in the cache, and, in addition, new TAGs connected with the occurrence of new cache keys are created (if it hasn’t previously occurred in a given TAG).
As a consequence, the amount of cache that we have at our disposal begins to decrease, as it is taken over by TAGs. If we add peak scale to the above, in which the application data is pushed in large amounts and TAGs continue to grow, we begin to have “not enough cache in cache”.
In our case, the scale reached the point when redis practically did nothing else but pushed the values and replaced them with new ones, expanding TAGs. Values were present in cache only for a moment before being pushed out by Redis – the cache appeared not to be working at all, although practically doing its job. That was the solution to our puzzle :)
To confirm the above, look at the statistical graphs of memory occupied by the application data (HASH) and TAGs (SET) for the cache just before the clog and for the correct cache:
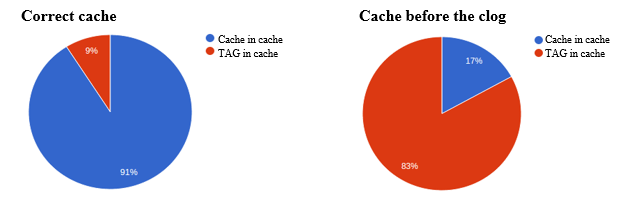
Solution
A workaround of the problem is adding to the schedule (cron) a script that will e.g. once a day clear the content of SET keys (tags) from HASH key names (application data stored in the cache) that don’t exist in the memory anymore. An example of a similar problem with the script is available here.
The ultimate goal should be to reduce the cache to a level that doesn’t trigger pushing keys (cache memory would not reach its maximum set value).
To do this, refactor the cache in order to get rid of the keys that may not be necessary (e.g. the cache exists on several levels, so the cache of the lowest level is not necessary because it already has a given value cached in the parent block).
Another step is manipulating the cache lifetime value. Perhaps these times are too long (e.g. a few days), the value is not often used and only takes up cache. The lifetime of the cache may be also not set at all, so the value is “immortal” (never expires) – such cases should be avoided.
It is worth setting a daily run for the script described above even if there are no problems with cache. The script clears redundant entries in key TAGs that are no longer present, thus reducing unnecessary data.
The result of refactoring should be stably performing cache, able to change its value by +/- a few hundred MB but never reaching the maximum set value – it will make our lives a lot easier :)
Published April 23, 2015










