

When it comes to enterprise software – theory and practice do not necessarily go along. If you’re wondering if microservices are a solution to the problem you’re facing, this post can help. I’m trying to answer some of the top questions regarding Microservices Architecture I’ve recently heard.
Are all APIs microservices?
Of course not. Microservices became a buzzword and therefore I’ve seen many products named as “microservices based” – even they’re just a monolith with some nice API.
When I spoke with Kelly Goetsch – CPO of commercetools how he defines a microservice he said that a microservice is an application, developed by a separate team, deployed on its own. These two factors are actually the most important benefits of a Microservices architecture because different teams are able to develop their parts and domain models not being tied to the other teams
“I’ve spent a lot of time in really big companies like Walmart and Oracle, and these are each 100 000 person plus companies. It was remarkable just how layered the organizations were so I don’t know how philosophical you want me to get here, but, you know, back in the day if you wanted to set up a database, you had to have a team of very highly skilled DBAs to do that.
Then you would build a DBA group and they would own the database and they didn’t want pesky developers like me touching their pretty database. [..]
If I had access to the database that’s a five second change. But in a big enterprise you have to go through a whole change request process, you have to fill out a whole bunch of paperwork and then they take the request, they implement it in a development environment, and then they give you access to the environment and then of course your access never actually works. [..] Then you have to verify it and they have some system that they use to manage their work where you have to mark as “done” in the workflow, then they promote it to QA and then they promote it to production and that’s why you end up having all of these project managers, because all you’re doing is coordinating the work across horizontal teams.
To take a feature from a middle-tier developer: If I had full access to that whole stack that’s a five-minute change, right? I go to the database I have the table, I go to the ORM, I expose that property, I add it there to the form handler whatever it is and then I go to multiple UIs and I just simply add it. That’s really easy if you had access to the whole stack”
When you take this definition you may easily realize that some of the services you’re working on are actually … macroservices – because of their scope. I guess it’s all OK – as long as the “team-per-service” condition is met. Philipp Triebel of HighSnobiety.com recently shared one of the insights they got from implementing the microservices architecture that they struggled with. the services were too granular to maintain, burdening the team with a high cost of daily routines, even deployments.
What are the downsides of the Microservices Architecture?
The microservices approach is subject to criticism due to a number of issues:
The architecture introduces additional complexity and new problems to deal with, such as network latency, message formats, load balancing, fault tolerance and monitoring. Ignoring one of these belongs to the “fallacies of distributed computing”.
The cost of the network traffic between microservices must also be taken into consideration, when using cloud solutions.
Automation is possible but in the simplest cases, tests and deployments may be more complicated than with a monolithic approach.
Moving responsibilities between services is difficult. It may involve communication between different teams, rewriting the functionality in another language or fitting it into a different infrastructure. On the other hand, it’s easy to test contracts between services after such changes.
Starting with the microservices approach from the beginning can lead to too many services, whereas the alternative of internal modularization may lead to a simpler design.
The problem with the services you own is that you need to keep them up and running. If you’ve got a small team (say less than 20 developers), it can be challenging to maintain, deploy, monitor, and keep the 24/7 SLA for a few dozen services. You need to have a DevOps inside your team.
The developers working on the software you deploy usually won’t be ready and won’t like to be on the pager 24/7 having the SSH terminal always on ready to react for any kind of issue their service will face. You must ensure the proper error and failure handling, network traffic balancing and redundancy. Then the team need to be in charge of the whole thing 24/7
What are the biggest risks of migrating to a service-oriented architecture?
It’s very easy to get into trouble with a services oriented architecture. The problem is complexity. In some extreme cases the microservices-based system can become unmaintainable, each new feature would require changes in a few different services – and deploying it altogether would become one big mess. Take just the answer to the subsequent question on “How is data consistency handled in microservices”. You get the idea.
First I’d recommend you looking at what draws you to microservices?
Perhaps your developers want something new and shiny to play with? Or maybe there was an article or some marketing material that presented it as the ultimate way of building the software of the future?
It’s worth noting that the problems with monoliths can be fixed without major re-architecting of your application. For example, Shopify started as a startup with a Ruby on Rails base and now they’re perhaps the only force in the world to compete with Amazon.
Ruby on Rails is well known for its flexibility with a “convention over configuration” approach that has just a few strict rules on designing the application. You can get results fast and it is a fun and productive way for developers to work. In fact, startups often choose Rails because they need to be fast, validate, and pivot. In essence, if Shopify had started with microservices architecture, complex deployment schemas, and complicated CI/devops processes, they may have failed.
Monolithic architecture is the easiest to implement. If no architecture is enforced, the result will likely be a monolith. This is especially true in Ruby on Rails, which lends itself nicely to building monoliths due to the global availability of all code at an application level. Monolithic architecture can take an application very far since it’s easy to build and allows teams to move very quickly in the beginning to get their product in front of customers earlier.
Maintaining the entire codebase in one place and deploying your application to a single place has many advantages. You’ll only need to maintain one repository, and be able to easily search and find all functionality in one folder. It also means only having to maintain one test and deployment pipeline, which, depending on the complexity of your application, may avoid a lot of overhead. These pipelines can be expensive to create, customize, and maintain because it takes concerted effort to ensure consistency across them all. Since all of the code is deployed in one application, the data can all live in a single shared database. Whenever a piece of data is needed, it’s a simple database query to retrieve it.
Source: Deconstructing the Monolith, Shopify blog
Are microservices a good idea for my new startup?
Regardless of whether your next application is gonna be modular, monolithic or microservices-based, it will use some services. The most important issue to resolve is which services you’d like to own and which you like to buy in order to keep out of the trouble and the hidden costs.
Having your application based on enterprise grade services—maintained and serviced by the provider—is a totally different situation to having your core business system fully decoupled and maintained by your team. I think that the power of the cloud computing is that you don’t have to take care of the details and can actually fully outsource the DevOps to the service provider.
The ownership problem is the key question to answer. The services businesses would like to have are the ones that make a difference for customers or are key to the business model. These change a lot; it may be the frontend application or the product configurator. They are usually the processes that are quite common and are not customized ones like invoicing, general ERP features, or WMS. These services increase your overall costs of ownership without giving back the proper business values. I’d recommend you to avoid owning these services and just integrate them altogether.
“No architecture is often the best architecture in the early days of a system […] It’s practical to trade off design quality for time to market. Once the speed at which you can add features and functionality begins to slow down, that’s when it’s time to invest in good design. The best time to refactor and re-architect is as late as possible, as you are constantly learning more about your system and business domain as you build. Designing a complex system of microservices before you have domain expertise is a risky move that too many software projects fall into.”
Source: Deconstructing the Monolith, Shopify blog
How is data consistency handled in microservices if each microservice has its own database?
Microservices that share a common database are – by some – named the anti pattern. Having a separate database per microservice – even at the cost of potential data-redundancy comes with unquestionable benefits:
- services can be separately deployed without any risks of the data structure conflicts,
- services can be scaled separately based on the usage patterns and the traffic,
- the domain model is simpler and easier to understand.
The open question here’s the data consistency model though. With a shared database one could potentially use SQL, ACID-compliant or even eventually consistent database like MongoDB and just use the built-in transactions engine.
With the distributed services things got a little bit more complex and the transaction management is the developer’s responsibility. There are at least a few patterns designed to solve this challenge.
Two-phase commit (2pc)
With this design pattern, a parent service is coordinating the sub-service calls – first executing the “prepare” phase of all subsequent actions (dry-run) and only after executing the actual operations. For example for the customers having a credit limit, the “prepare” step can be used to check if there’s a sufficient credit limit (and potentially reserve this limit for the order operation). Then we can prepare the order itself (reserving the product stocks). If all steps succeed the order is ready to be placed – on risk and therefore complexity of returning the previous state (reverting) before the transaction.
This pattern is pretty easy to implement however it does not support long-lasting transactions as the subsequent steps are usually just synchronous calls. Moreover, if the prepare step is blocking some resources (reservations in order to prepare the commit call) in case of the failure 2pc may lead to deadlocks (bc. the resources – in this example the credit limit – is not return to the previous state on time)
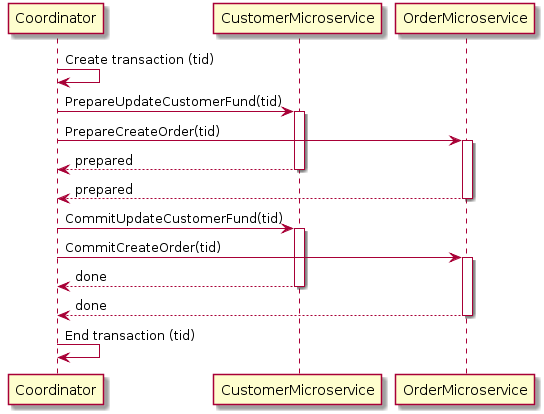
Example of the 2pc pattern in action. Source: https://developers.redhat.com/blog/2018/10/01/patterns-for-distributed-transactions-within-a-microservices-architecture/
Saga pattern
To solve these problems that might occur using two phase commits you may decide to implement the Saga pattern.
Usually the event bus / queue is used to implement it and the pattern by its nature is fully asynchronous. Actually the way it works is very similar to the way Event Sourcing works.
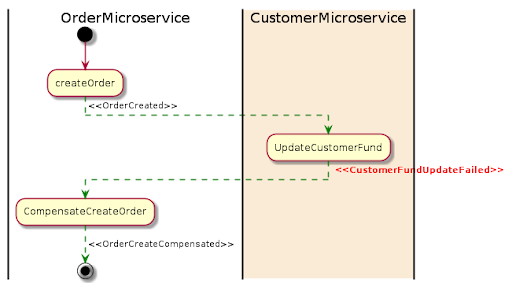
With the Saga pattern we’re leveraging the event-based development in which the success and failure handlers are in charge of commiting and reverting any changes made to the data source.
In the example above, the OrderMicroservice receives a request to place an order. It first starts a local transaction to create an order and then emits an OrderCreated event. The CustomerMicroservice listens for this event and updates a customer fund once the event is received. If a deduction is successfully made from a fund, a CustomerFundUpdated event will then be emitted, which in this example means the end of the transaction.
If any microservice fails to complete its local transaction, the other microservices will run compensation transactions to rollback the changes.
Source: https://developers.redhat.com/blog/2018/10/01/patterns-for-distributed-transactions-within-a-microservices-architecture/
Published January 18, 2021









